Programación modular (I)
Ricardo Pérez López
IES Doñana, curso 2024/2025
1 Introducción
1.1 Modularidad
La programación modular es una técnica de programación que consiste en descomponer nuestro programa en partes llamadas módulos y escribir cada módulo por separado.
- El concepto de módulo hay que entenderlo en sentido amplio: cualquier parte de un programa se podría considerar «módulo».
Equivale a la técnica clásica de resolución de problemas basada en:
- Descomponer un problema en subproblemas.
- Resolver cada subproblema por separado.
- Combinar las soluciones para así obtener la solución al problema original.
La modularidad es la propiedad que tienen los programas escritos siguiendo los principios de la programación modular.
Las técnicas de modularidad y descomposición de problemas se aplican en la mayoría de las disciplinas científicas e industriales.
Por ejemplo, el diseño y fabricación de un coche resulta complicado si vemos a éste como un todo (un conglomerado de piezas todas juntas).
Además, desde ese punto de vista sería difícil poder reparar una avería, ya que la sustitución de cualquier pieza podría afectar a cualquier otra parte del coche, a menudo de formas poco evidentes.
En cambio, el coche resulta mucho más fácil de entender si lo descomponemos en partes, estudiamos cada parte por separado y definimos claramente cómo interactúa cada parte con las demás.
Esas partes (que aquí llamamos módulos) son componentes más o menos independientes que interactúan con otros componentes de una manera bien definida. Por ejemplo:
- Frenos
- Luces
- Climatización
- Dirección
- Motor
- Carrocería
El objetivo es convertir la programación es una tarea que consista en ir fabricando y ensamblando bloques constructivos que tengan sentido por sí mismos, que lleven a cabo una función concreta y que, al combinarlos adecuadamente, nos dé como resultado el programa que queremos desarrollar.
Para alcanzar ese objetivo, el concepto de modularidad se puede estudiar a nivel metodológico y a nivel práctico.
A nivel metodológico, la modularidad nos proporciona una herramienta más para controlar la complejidad (como la abstracción, que de hecho puede servir como técnica que guíe la modularización).
Todos los mecanismos de control de la complejidad actúan de la misma forma: la mente humana es incapaz de mantener la atención en muchas cosas a la vez, así que lo que hacemos es centrarnos en una parte del problema y dejamos a un lado el resto momentáneamente.
La abstracción nos permite controlar la complejidad permitiéndonos estudiar un problema o su solución por niveles, centrándonos en lo esencial e ignorando los detalles que a ese nivel resultan innecesarios.
Con la modularidad buscamos descomponer conceptualmente el programa en partes que se puedan estudiar y programar por separado, de forma más o menos independiente, lo que se denomina descomposición lógica.
Ambos conceptos son combinables, como veremos luego.
A nivel práctico, la modularidad nos ofrece una herramienta que nos permite partir el código del programa en partes más manejables.
A medida que los programas se hacen más y más grandes, el esfuerzo de mantener todo el código dentro de un único script se hace mayor.
No sólo resulta incómodo mantener todo el código en un mismo archivo, sino que además resulta intelectualmente más difícil de entender.
Lo más práctico es repartir el código fuente de nuestro programa en una colección de archivos fuente que se puedan trabajar por separado, lo que se denomina descomposición física.
Esto, además, nos va a permitir que un programa pueda ser desarrollado conjuntamente por varias personas al mismo tiempo, cada una de ellas responsabilizándose de escribir uno o varios módulos del mismo programa.
Esos módulos se podrán escribir de forma más o menos independiente aunque, por supuesto, estarán relacionados entre sí, ya que unos consumirán los servicios que proporcionan otros.
Un módulo es, pues, una parte de un programa que se puede estudiar, entender y programar por separado con relativa independencia del resto del programa.
Por tanto, podría decirse que una función es un ejemplo de módulo, ya que se ajusta a esa definición (salvo quizás que no habría descomposición física, aunque se podría colocar cada función en un archivo separado y entonces sí).
Sin embargo, descomponer un programa en partes usando únicamente como criterio la descomposición en funciones no resulta adecuado en general, ya que muchas veces nos encontramos con varias funciones que no actúan por separado, sino de forma conjunta entre ellas formando un todo interrelacionado.
Además, un módulo no tiene por qué ser simplemente una abstracción funcional, sino que también puede tener su propio estado interno en forma de datos almacenados en variables y constantes, manipulables desde dentro del módulo y posiblemente también desde fuera.
Por ejemplo, supongamos un conjunto de funciones que manipulan números racionales.
Tendríamos funciones para crear racionales, para sumarlos, para multiplicarlos, para simplificarlos, etc.
Todas esas funciones trabajarían conjuntamente, incluso usándose unas a otras, y actuarían sobre colecciones de datos que representarían números racionales de una forma apropiada.
Por consiguiente, aunque resulta muy apropiado considerar cada función anterior por separado, es más conveniente considerarlas como un todo: el módulo de manipulación de números racionales.
Otro ejemplo: supongamos un módulo encargado de realizar operaciones trigonométricas sobre ángulos.
Esos ángulos serían números reales que podrían representar grados o radianes.
Ese módulo contendría las funciones encargadas de calcular el seno, coseno, tangente, etc. de un ángulo pasado como parámetro a cada función.
Para ello, el módulo podría contener un dato (almacenado en una variable dentro del módulo) que indicará si las funciones anteriores deben interpretar los ángulos como grados o como radianes.
Ese dato constituiría el estado interno del módulo, al ser un valor que se almacena dentro del mismo módulo (pertenece a éste) y puede cambiar su comportamiento dependiendo del valor que tenga el dato.
Además, probablemente también necesite conocer el valor de \pi, que podría almacenar el módulo internamente como una constante.
De lo dicho hasta ahora se deducen varias conclusiones importantes:
Un módulo es una parte de un programa.
Los módulos nos permiten descomponer el programa en partes más o menos independientes y manejables por separado.
Una función cumple con la definición de «módulo» pero, en general, en la práctica no es una buena candidata para ser considerada un módulo por sí sola.
Los módulos, en general, agrupan colecciones de funciones interrelacionadas.
Los módulos, además de funciones, pueden contener datos en forma de constantes y variables manipulables desde el interior del módulo así como desde el exterior del mismo usando las funciones que forman el módulo.
Las variables del módulo constituyen el estado interno del módulo.
A nivel práctico, los módulos se programan físicamente en archivos separados del resto del programa.
1.2 Beneficios de la programación modular
El tiempo de desarrollo se reduce porque grupos separados de programadores pueden trabajar cada uno en un módulo con poca necesidad de comunicación entre ellos.
Se mejora la productividad del producto resultante, porque los cambios (pequeños o grandes) realizados en un módulo no afectarían demasiado a los demás.
Comprensibilidad, porque se puede entender mejor el sistema completo cuando se puede estudiar módulo a módulo en lugar de tener que estudiarlo todo a la vez.
2 Diseño modular
2.1 Creadores y usuarios
Desde la perspectiva de la programación modular, un programa está formado por una colección de módulos que interactúan entre sí.
Puede decirse que un módulo proporciona una serie de servicios que son usados o consumidos por otros módulos del programa.
Así que podemos estudiar el diseño de un módulo desde dos puntos de vista complementarios:
El creador o implementador del módulo es la persona encargada de la programación del mismo y, por tanto, debe conocer todos los detalles internos del módulo, necesarios para que éste funcione. Esos detalles internos constituyen la implementación del módulo.
Los usuarios del módulo son los programadores que desean usar ese módulo en sus programas. También se les llama así a los módulos de un programa que usan a ese módulo (lo necesitan para funcionar).
A la parte del módulo que es accesible directamente desde fuera del mismo se le denomina la interfaz del módulo.
Los módulos exportan su interfaz al resto de los módulos.
Los módulos usuarios deben importar un módulo para poder usarlo. Al hacerlo, tienen acceso a los elementos exportados por el módulo a través de su interfaz, lo que le permite al módulo usuario consumir los servicios que proporciona el módulo importado.
En terminología de programación modular, hablamos entonces de la existencia de dos tipos de módulos:
El que usa a otro módulo es el módulo «usuario», «cliente», «consumidor» o «importador».
El que es usado por otro módulo es el módulo «usado», «servidor», «consumido» o «importado».
Los usuarios de un módulo están interesados en usar dicho módulo como una entidad abstracta, sin necesidad de conocer los detalles internos del mismo, sino conociendo sólo lo necesario para poder consumir los servicios que proporciona (es decir, su interfaz).
Esos usuarios consumirán los servicios del módulo a través de su interfaz, la cual oculta a los usuarios los detalles internos de funcionamiento que no es necesario conocer para usar el módulo.
Esos detalles internos forman la implementación del módulo y sólo son interesantes para (y sólo deben ser conocidos por) el creador del módulo.
Por supuesto, un módulo puede usar a otros módulos y, al mismo tiempo, ser usado por otros módulos. Por tanto, el mismo módulo puede ser importador e importado simultáneamente.
Los miembros o elementos de un módulo son aquellos elementos que forman parte del módulo.
En general, a la hora de describir las partes de un módulo, distinguimos entre miembros públicos y miembros privados:
Los miembros públicos o exportados de un módulo son aquellos miembros que están diseñados para ser usados fuera del módulo por los usuarios del mismo.
Estos miembros (al menos, las especificaciones de los mismos, es decir, lo necesario para poder usarlos) deben formar parte de la interfaz del módulo.
Los miembros privados o internos de un módulo son aquellos miembros que están diseñados para ser usados únicamente por el propio módulo y, por tanto, no deberían ser usados (ni siquiera conocidos) fuera del módulo.
Estos miembros NO deben formar parte de la interfaz del módulo, sino que deben ir en la implementación del módulo.
2.2 Partes de un módulo
Concretando lo dicho anteriormente, un módulo tendrá:
Una interfaz, formada por:
El nombre del módulo.
Las signaturas de sus funciones exportadas o públicas que permiten a los usuarios consumir sus servicios, así como manipular y acceder al estado interno del módulo desde fuera del mismo.
Es posible que la interfaz también incluya constantes públicas.
Una implementación, formada por:
Las implementaciones de sus funciones públicas.
Posibles variables locales al módulo (el estado interno de éste).
Posibles funciones internas o privadas, que no aparecen en la interfaz porque están pensadas para ser usadas sólo por el propio módulo internamente, no por otras partes del programa.
Otros miembros privados, como constantes privadas.
Lo anterior es una simplificación, ya que, dependiendo de las características del lenguaje de programación utilizado, un módulo puede tener miembros pertenecientes a muchas otras categorías sintácticas, como por ejemplo:
Tipos.
Clases.
Otros módulos.
Todos esos miembros pueden formar parte de la interfaz o de la implementación del módulo, dependiendo de las necesidades del mismo, y ser, por tanto, miembros públicos o privados de éste.
También se admiten otras combinaciones más complicadas. Por ejemplo, si alguno de esos miembros es público, su especificación podría formar parte de la interfaz del módulo, mientras que su implementación podría formar parte de la implementación del módulo.
2.2.1 Interfaz
La interfaz es la parte del módulo que es accesible directamente desde fuera del mismo.
Por tanto, es la parte a través de la cual el módulo ofrece sus servicios a sus usuarios, que sólo podrán acceder al mismo a través de su interfaz.
Es la parte expuesta, pública o visible del mismo.
También se la denomina su API (Application Program Interface).
La interfaz es la parte del módulo que éste exporta a los demás módulos del programa, que son sus posibles usuarios.
En general debería estar formada únicamente por funciones (y, tal vez, constantes) que el usuario del módulo pueda llamar para consumir los servicios que ofrece el módulo.
No todas las funciones definidas en un módulo tienen por qué formar parte de la interfaz del mismo. Las que sí lo hacen son las denominadas funciones públicas o exportadas.
2.2.1.1 Especificación
La interfaz es un concepto puramente sintáctico.
Describe la sintaxis (nombre y tipos) de los elementos del módulo a los que se puede acceder desde fuera del mismo.
Pero sólo con eso, el usuario no tiene toda la información que necesita para poder usar el módulo.
Para ello, también necesita saber qué hace el módulo, y qué hacen las funciones que forman la interfaz del módulo.
La especificación del módulo representa toda la información que el usuario del mismo necesita conocer para poder utilizarlo.
La especificación de un módulo está formada por:
La interfaz del módulo.
La especificación de todas las funciones que aparecen en la interfaz.
Documentación adicional que describa lo que hace el módulo y que aporte al usuario cualquier información extra que necesite saber para poder usar el módulo sin tener que conocer o acceder a partes internas del mismo.
Aquí podría incluirse documentación sobre el módulo en sí, así como sobre las funciones y las constantes públicas que aparecen en la interfaz, escrita en lenguaje natural y de fácil comprensión para el lector humano, añadiendo posibles ejemplos de uso.
Desde el punto de vista de los usuarios del módulo, las funciones son abstracciones funcionales, de forma que, para poder usarlas, sólo se necesita conocer las especificaciones de esas funciones y no sus implementaciones concretas (sus definiciones completas).
Recordemos que la especificación de una función está formada por tres partes:
Precondición: la condición que se debe cumplir al llamar a la función.
Signatura: los aspectos meramente sintácticos como el nombre de la función, el nombre y tipo de sus parámetros y el tipo de su valor de retorno.
Postcondición: la condición que se cumplirá al finalizar su ejecución.
Por tanto, la especificación del módulo contendrá las especificaciones de las funciones públicas, pero no sus implementaciones.
Acabamos de decir que la interfaz de un módulo debería estar formada únicamente por funciones y, tal vez, constantes.
En teoría, la interfaz podría incluir también algunas o todas las variables locales al módulo, de forma que el módulo usuario podría acceder y modificar directamente una variable del módulo usado.
Sin embargo, en la práctica eso no resulta apropiado, ya que:
Cambiar el valor de una variable local a un módulo equivale a modificar una variable global (ya que existen en el ámbito global del módulo) y, por tanto, se considera un efecto lateral.
Cualquier cambio posterior en la representación interna de los datos almacenados en esas variables afectaría al resto de los módulos que acceden a dichas variables.
Las constantes sí se admiten ya que nunca cambian su valor y, por tanto, están exentas de posibles efectos laterales.
Más adelante estudiaremos este aspecto en profundidad cuando hablemos del principio de ocultación de información.
2.2.2 Implementación
La implementación es la parte del módulo que queda oculta a los usuarios del mismo.
Por tanto, es la parte que los usuarios del módulo no necesitan (ni deben) conocer para poder usarlo adecuadamente.
Está formada por:
La implementación de las funciones que forman la interfaz.
Todas las variables locales al módulo que almacenan su estado interno, si las hay.
Las funciones que utiliza el propio módulo internamente y que no forman parte de su interfaz (funciones internas o privadas), si las hay.
Posibles constantes privadas, usadas sólo por el propio módulo.
La implementación debe poder cambiarse tantas veces como sea necesario sin que por ello se tenga que cambiar el resto del programa.
2.2.2.1 Resumen
\text{Interfaz del módulo}\begin{cases} \text{Nombre del módulo}\\ \text{Signatura de las funciones públicas}\\ \text{Posibles constantes públicas} \end{cases}
\text{Especificación del módulo}\begin{cases} \text{Interfaz del módulo}\\ \text{Especificación de las funciones de la interfaz}\\ \text{Documentación adicional} \end{cases}
\text{Implementación del módulo}\begin{cases} \text{Implementación de las funciones públicas}\\ \text{Posibles variables locales}\\ \text{Posibles funciones privadas} \\ \text{Posibles constantes privadas} \end{cases}
2.3 Diagramas de estructura
Los diferentes módulos que forman un programa y la relación que hay entre ellos se puede representar gráficamente mediante un diagrama de descomposición modular o diagrama de estructura.
En el diagrama de estructura, cada módulo se representa mediante un rectángulo y las relaciones entre cada par de módulos se dibujan como una línea con punta de flecha entre los dos módulos.
Una flecha dirigida del módulo A al módulo B representa que el módulo A utiliza (o llama o consume) al módulo B, o también se puede decir que el módulo A depende del módulo B.


Al módulo A se le denomina módulo principal, ya que es el módulo por el que comienza la ejecución del programa.
El módulo principal depende, directa o indirectamente, de los demás módulos del programa.
No hay ningún módulo que dependa del módulo principal.
3 Programación modular en Python
3.1 Scripts como módulos
En Python, un módulo es otra forma de llamar a un script. Es decir: «módulo» y «script» son sinónimos en Python.
Los módulos contienen instrucciones: definiciones y otras sentencias.
El nombre del archivo es el nombre del módulo con extensión
.py.Eso quiere decir que un módulo se puede ejecutar de dos maneras:
Como un script independiente, llamándolo desde la línea de órdenes del sistema operativo (sería el módulo principal):
Importándolo dentro de otros módulos que quieran usar los servicios que proporciona, usando la sentencia
import(ofrom ... import):
Las sentencias que contiene un módulo se ejecutan sólo la primera vez que se encuentra el nombre de ese módulo en una sentencia
import, o bien cuando el archivo se ejecuta como un script.Dentro de un módulo, el nombre del módulo (como cadena) se encuentra almacenado en la variable global
__name__.Cada módulo determina su propio ámbito local, que es usado como el ámbito global de todas las instrucciones que componen el módulo.
Además, los módulos son espacios de nombres.
Por tanto, el autor de un módulo puede definir variables globales o funciones en el módulo sin preocuparse de posibles colisiones accidentales con las variables globales o funciones de otros módulos.
Esas variables y funciones serán los atributos del objeto módulo que se creará si se importa el módulo con la sentencia
import.
Al entrar en un módulo para ejecutar sus sentencias, se entra en un nuevo ámbito que constituirá el ámbito global del módulo.
Además, se creará un nuevo marco encima de la pila, que constituirá el nuevo marco global durante la ejecución del módulo.
Los demás marcos que pudieran existir antes de ejecutar el módulo (por ejemplo, el marco global del script que ha importado el módulo) seguirán más abajo en la pila, pero no serán accesibles desde el módulo actual.
Esos marcos quedan fuera del entorno y se recuperarán al finalizar la ejecución del módulo importado.
Igualmente, los ámbitos que existieran antes de importar un módulo (incluyendo el ámbito global del script que ha importado al módulo) quedan temporalmente invalidados al encontrarse en archivos fuente distintos, y se recuperarán al finalizar la ejecución del módulo y volver al archivo fuente anterior.
3.2 Importación de módulos
Para que un módulo pueda usar a otros módulos tiene que importarlos usando la orden
import. Por ejemplo, la siguiente sentencia importa el módulomathdentro del ámbito actual:Al importar un módulo de esta forma, se incorpora al espacio de nombres actual (que suele ser el marco del script o función que se está ejecutando actualmente) la ligadura entre el nombre del módulo importado y el propio módulo, el cual es es un objeto de tipo
module.De esta forma, lo que se importa dentro del espacio de nombres actual es una referencia al objeto módulo.
Por ejemplo, si tenemos los siguientes scripts (o módulos, que es lo mismo en Python)
uno.pyydos.py, y empezamos a ejecutaruno.py:Al ejecutar la línea 3 tendremos el siguiente entorno:

uno- Al ejecutar
import dosen la línea 5 deuno.py, pasaremos a ejecutar el scriptdos.pyy el marco global del entorno será ahora el marco global dedos. Los marcos creados hasta ahora durante la ejecución deuno(incluyendo el marco global deuno) no estarán en el entorno:

dos durante su
importación en uno- Al finalizar la ejecución del script
dos.py, el marco global dedosse convierte en un objeto de tipomoduleen el montículo, y sus ligaduras se convierten en atributos del objeto. Ese objeto se ligará al identificadordosen el marco global deuno, que volverá a estar en el entorno y pasará a ser de nuevo el marco global del entorno:

import dos- Finalmente, tras ejecutar todo el script
uno.pytendríamos el siguiente entorno:

uno- Recordemos que, siempre que tengamos una referencia a un objeto,
podemos acceder a los atributos que contiene usando el operador punto
(
.), indicando el objeto y el nombre del atributo al que queramos acceder:
objeto.atributo
- Por tanto, para acceder al contenido del módulo importado,
indicaremos el nombre de ese módulo seguido de un punto (
.) y el nombre del contenido al que queramos acceder:
módulo.contenido
Por ejemplo, para acceder a la función
gcddefinida en el módulomath, haremos:

- Se recomienda por regla de estilo (aunque no es obligatorio) colocar
todas las sentencias
importal principio del módulo importador.
Se puede importar un módulo dándole otro nombre dentro del espacio de nombres actual, usando la sentencia
import ... as.Por ejemplo:
La sentencia anterior importa el módulo
mathdentro del espacio de nombres actual pero con el nombrematesen lugar delmathoriginal. Por tanto, para usar la funcióngcddel ejemplo anterior, haremos:

Existe una variante de la sentencia
importque nos permite importar directamente las definiciones de un módulo en lugar del propio módulo. Para ello, se usa la ordenfrom.Por ejemplo, para importar sólo la función
gcddel módulomath, y no el módulo en sí, haremos:Por lo que ahora podemos usar la función
gcddirectamente, sin necesidad de indicar el nombre del módulo importado:

De hecho, ahora el módulo importado no está definido en el módulo importador.
Ees decir: ahora en el marco global del módulo importador no hay ninguna ligadura con el nombre del módulo importado.
En nuestro ejemplo, eso significa que el módulo
mathno existe ahora como tal en el módulo importador y, por tanto, ese nombre no está definido en el ámbito del módulo importador.En consecuencia, si hacemos:
da error, porque no hemos importado el módulo como tal, sino sólo una de sus funciones.
También podemos usar la palabra clave
ascon la ordenfrom:De esta forma, se importa en el módulo actual la función
gcddel módulomathpero llamándolamcd.Por tanto, para usarla la invocaremos con su nuevo nombre:

Existe incluso una variante para importar todas las definiciones de un módulo:
Con esta sintaxis importaremos todas las definiciones del módulo excepto aquellas cuyo nombre comience por un guión bajo (
_).Las definiciones con nombres que comienzan por
_son consideradas privadas o internas al módulo, lo que significa que no están concebidas para ser usadas por los usuarios del módulo y que, por tanto, no forman parte de su interfaz (no deben usarse fuera del módulo).En general, los programadores no suelen usar esta funcionalidad ya que puede introducir todo un conjunto de definiciones desconocidas dentro del módulo importador, lo que incluso puede provocar que se «machaquen» sin control definiciones ya existentes.
Para saber qué definiciones (públicas o privadas) contiene un módulo, se puede usar la funcion
dir:>>> import math >>> dir(math) ['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']La función
dirpuede usarse con cualquier objeto al que podamos acceder a través de una referencia.
3.3 Módulos como scripts
Cuando se ejecuta un módulo Python desde la línea de órdenes como:
se ejecutará el módulo como un script, igual que si se hubiera importado con un
importdentro de otro módulo, pero con la diferencia de que la variable global__name__contendrá el valor"__main__".Eso indica que ese script se considera el módulo principal (en inglés, main module) del programa.
Por eso, si se añade este código al final del módulo:
esas sentencias se ejecutarán únicamente cuando el módulo se ejecute como el módulo principal del programa.
Por ejemplo, supongamos el siguiente módulo
fact.py:Este módulo se podrá usar como un script separado o como un módulo que se puede importar dentro de otro.
Si se usa como script, podremos llamarlo desde la línea de órdenes del sistema operativo:
Y si importamos el módulo dentro de otro, la condición del último
ifno se cumplirá, por lo que su único efecto será el de incorporar la definición de la funciónfacdentro del módulo importador.
3.4 La librería estándar
La librería estándar de Python contiene módulos predefinidos que proporcionan:
Acceso a funcionalidades del sistema, como operaciones de E/S sobre archivos.
Soluciones estandarizadas a muchos de los problemas que los programadores pueden encontrarse en su día a día.
Algunos módulos están diseñados explícitamente para promover y mejorar la portabilidad de los programas Python abstrayendo los aspectos específicos de cada plataforma a través de un API independiente de la plataforma.
- La documentación contiene la información más completa sobre el contenido de la librería estándar, a la que podemos acceder a través de la siguiente dirección:
https://docs.python.org/3/library/index.html
En esa dirección, además, se incluye información sobre:
Funciones, constantes, excepciones y tipos predefinidos, que también forman parte de la librería estándar.
Componentes opcionales que habitualmente podemos encontrar en cualquier instalación de Python.
4 Criterios de descomposición modular
4.1 Introducción
No existe una única forma de descomponer un programa en módulos (entendiendo aquí por módulo cualquier parte del programa en sentido amplio, incluyendo una simple función).
Las diferentes formas de dividir el sistema en módulos traen consigo diferentes requisitos de comunicación y coordinación entre las personas (o equipos) que trabajan en esos módulos, y ayudan a obtener los beneficios descritos anteriormente en mayor o menor medida.
Nos interesa responder a las siguientes preguntas:
¿Qué criterios se deben seguir para dividir el programa en módulos?
¿Qué módulos debe tener nuestro programa?
¿Cuántos módulos debe tener nuestro programa?
¿De qué tamaño deben ser los módulos?
4.2 Tamaño y número
Se supone que, si seguimos al pie de la letra la estrategia de diseño basada en la división de problemas, sería posible concluir que si el programa se dividiera indefinidamente, cada vez se necesitaría menos esfuerzo hasta llegar a cero.
Evidentemente, esto no es así, ya que hay otras fuerzas que entran en juego.
El coste de desarrollar un módulo individual disminuye conforme aumenta el número de módulos.
Por otra parte, dado el mismo conjunto de requisitos funcionales, cuantos más módulos hay, más pequeños son.
Sin embargo, cuantos más módulos hay, más cuesta integrarlos.
El tamaño de cada módulo debe ser el adecuado: si es demasiado grande, será difícil hacer cambios en él; si es demasiado pequeño, no merecerá la pena tratarlo como un módulo, sino más bien como parte de otros módulos.
- El valor M es el número de módulos ideal, ya que reduce el coste total del desarrollo.
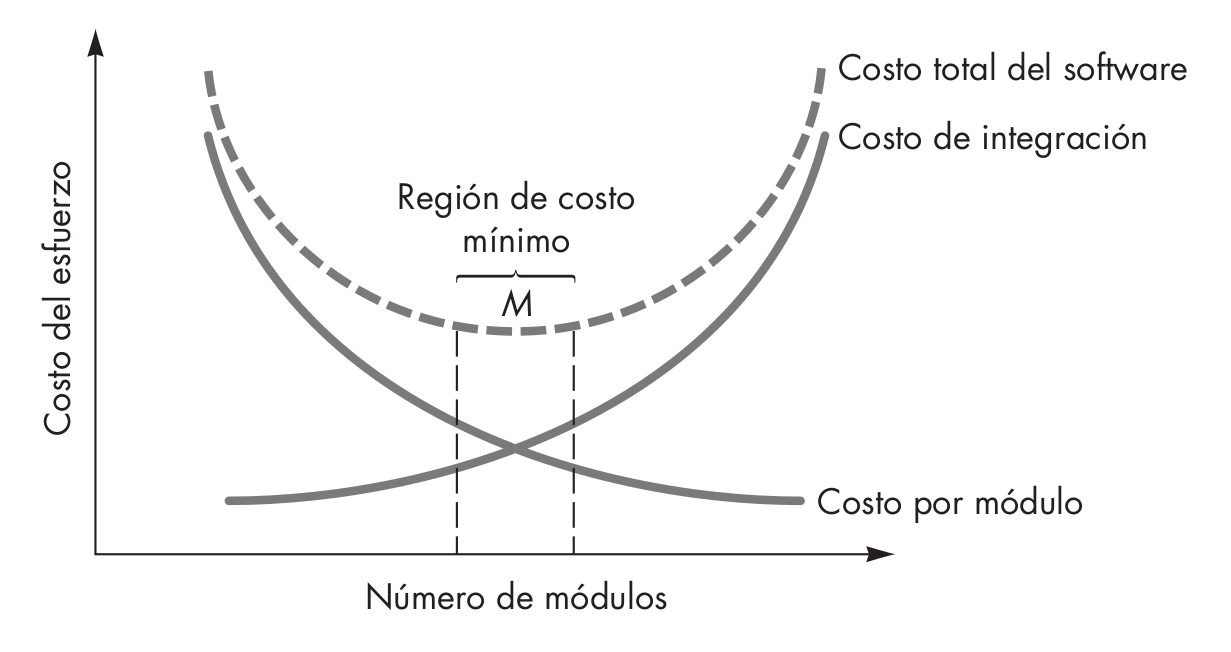
Las curvas de la figura anterior constituyen una guía útil al considerar la modularidad.
Debemos evitar hacer pocos o muchos módulos para así permanecer en la cercanía de M.
Pero, ¿cómo saber cuál es la cercanía de M? ¿Cómo de modular debe hacerse el programa?
Debe hacerse un diseño con módulos, de manera que el desarrollo pueda planearse con más facilidad, que los cambios se realicen con más facilidad, que las pruebas y la depuración se efectúen con mayor eficiencia y que el mantenimiento a largo plazo se lleve a cabo sin efectos indeseados de importancia.
Para ello nos basaremos en los siguientes criterios.
4.3 Abstracción
La abstracción es un proceso mental que se basa en estudiar un aspecto del problema a un determinado nivel centrándose en lo esencial e ignorando momentáneamente los detalles que no son importantes en este nivel.
Ese proceso nos permite comprender la esencia de un subsistema sin tener que conocer detalles innecesarios del mismo.
Es decir, se puede estudiar y usar el subsistema sabiendo qué hace sin tener que saber cómo lo hace.
La utilización de la abstracción también permite trabajar con conceptos y términos que son familiares en el entorno del problema sin tener que transformarlos en una estructura no familiar.
La abstracción se usa principalmente como una técnica de manejo y control de la complejidad.
Cuando se considera una solución modular a cualquier problema, se pueden definir varios niveles de abstracción:
En niveles más altos de abstracción, se enuncia una solución en términos más generales usando el lenguaje del entorno del problema.
A estos niveles hay menos elementos de información, pero más grandes e importantes.
En niveles más bajos de abstracción se da una descripción más detallada de la solución.
A estos niveles se revelan más detalles, aparecen más elementos y se aumenta la cantidad de información con la que tenemos que trabajar.
| Nivel 1 | (Más abstracción) |
| Nivel 2 | |
| Nivel 3 | |
| … | |
| Nivel n | (Más detalle) |
La barrera de separación entre un nivel de abstracción y su inmediatamente inferior es la diferencia entre el qué y el cómo:
Cuando estudiamos un concepto a un determinado nivel de abstracción, estudiamos qué hace.
Cuando bajamos al nivel inmediatamente inferior, pasamos a estudiar cómo lo hace.
Esta división o separación puede continuar en niveles inferiores, de forma que siempre puede considerarse que cualquier nivel responde al qué y el nivel siguiente (el que está justo debajo) responde al cómo.
Recordemos que un módulo tiene siempre un doble punto de vista:
El punto de vista del creador o implementador del módulo.
El punto de vista del usuario del módulo.
La abstracción nos ayuda a definir qué módulos constituyen nuestro programa considerando la relación que se establece entre los creadores y los usuarios de los módulos.
Esto es así porque los usuarios de un módulo quieren usar a éste como una abstracción: sabiendo qué hace (su función) pero sin necesidad de saber cómo lo hace (sus detalles internos).
El responsable del cómo es únicamente el creador del módulo.
Los módulos definidos como abstracciones son más fáciles de usar, diseñar y mantener.
4.4 Ocultación de información
David Parnas introdujo el principio de ocultación de información en 1972.
Afirmó que el criterio principal para la modularización de un sistema debe ser la ocultación de decisiones de diseño complejas o que puedan cambiar en el futuro, es decir, que los módulos se deben caracterizar por ocultar decisiones de diseño a los demás módulos.
Por tanto: todos los elementos que necesiten conocer las mismas decisiones de diseño, deben pertenecer al mismo módulo.
Al ocultar la información de esa manera se evita que los usuarios de un módulo necesiten de un conocimiento íntimo del diseño interno del mismo para poder usarlo, y los aísla de los posibles efectos de cambiar esas decisiones posteriormente.
Implica que la modularidad efectiva se logra definiendo un conjunto de módulos independientes que intercambien sólo aquella información estrictamente necesaria para que el programa funcione.
Dicho de otra forma:
Para que un módulo A pueda usar a otro B, A tiene que conocer de B lo menos posible, lo imprescindible.
El uso del módulo debe realizarse únicamente por medio de interfaces bien definidas que no cambien (o cambien poco) con el tiempo y que no expongan detalles internos al exterior.
Por tanto, B debe ocultar al exterior sus detalles internos de implementación y exponer sólo lo necesario para que otros lo puedan utilizar.
Ésto aísla a los usuarios de los posibles cambios internos que pueda haber posteriormente en B.
Es decir: cada módulo debe ser una caja negra recelosa de su privacidad que tiene «aversión» por exponer sus interioridades a los demás.
La abstracción y la ocultación de información se complementan:
La abstracción puede usarse como una técnica de diseño que nos da un método para descomponer el programa en módulos. Es decir: nos ayuda a decidir qué módulos debe tener el programa.
Pero también nos dice qué debe ocultar y qué debe exponer cada módulo, porque afirma que la interfaz debe estar formada, precisamente, por lo elementos que responden al «qué» hace el módulo, y la implementación por los que responden al «cómo» lo hace.
La ocultación de información es un principio de diseño que se basa en que los módulos deben ocultar a los demás módulos sus decisiones de diseño y exponer sólo la información estrictamente necesaria para que los demás puedan usarlos.
Por tanto, nos ayuda a identificar qué detalles debe ocultar el módulo y qué información debe exponer a los demás. Es decir: qué detalles internos deben conocerse de un módulo para poder usarlo.
También nos ayuda a ver en qué módulo va cada elemento del programa. Es decir: qué elementos deben formar parte de un módulo y cuáles deben formar parte de otros módulos.
Al usuario de un módulo…
… le interesa la abstracción porque le permite usar el módulo sabiendo únicamente qué hace sin tener que saber cómo lo hace.
… le interesa la ocultación de información porque cuanta menos información necesite conocer para usar el módulo, menos expuesto estará a verse afectado por posibles cambios futuros en el funcionamiento interno del mismo.
Al creador de un módulo…
… le interesa la abstracción porque le ayuda a determinar qué módulos deben formar parte del programa.
… le interesa la ocultación de información porque le ayuda a determinar qué elementos deben formar parte de su módulo y qué información debe ocultar su módulo al exterior. Además, cuantos menos detalles necesiten conocer los usuarios para poder usar su módulo, más libertad tendrá él para cambiar esos detalles en el futuro (cuando lo necesite o lo desee) sin afectar a los usuarios de su módulo.
4.5 Independencia funcional
La independencia funcional es otro criterio a seguir para obtener una modularidad efectiva.
La independencia funcional se logra desarrollando módulos de manera que cada módulo resuelva una funcionalidad específica y tenga una interfaz sencilla cuando se vea desde otras partes de del programa (idealmente, mediante paso de parámetros).
- De hecho, la interfaz del módulo debe estar destinada únicamente a cumplir con esa funcionalidad.
Al limitar su objetivo, el módulo necesita menos ayuda de otros módulos.
Por ello, el módulo debe ser tan independiente como sea posible del resto de los módulos del programa.
Es decir: debe depender lo menos posible de lo que hagan otros módulos, y también debe depender lo menos posible de los datos que puedan facilitarle otros módulos.
Dicho de otra forma: los módulos deben centrarse en resolver un problema concreto (ser «monotemáticos»), deben ser «antipáticos», tener «aversión» a relacionarse con otros módulos y depender lo menos posible de otros módulos.
Los módulos independientes son más fáciles de desarrollar porque la función del programa se subdivide y las interfaces se simplifican, por lo que se pueden desarrollar por separado.
Los módulos independientes son más fáciles de mantener y probar porque los efectos secundarios causados por el diseño o por la modificación del código son más limitados, se reduce la propagación de errores y es posible obtener módulos reutilizables.
De esta forma, la mayor parte de los cambios y mejoras que haya que hacer al programa implicarán modificar sólo un módulo o un número muy pequeño de ellos.
Es un objetivo a alcanzar para obtener una modularidad efectiva.
La independencia funcional se mide usando dos métricas: la cohesión y el acoplamiento.
El objetivo de la independencia funcional es maximizar la cohesión y minimizar el acoplamiento.
4.5.1 Cohesión
La cohesión mide la fuerza con la que se relacionan los componentes de un módulo.
Cuanto más cohesivo sea un módulo, mejor será nuestro diseño modular.
Un módulo cohesivo realiza una sola función, por lo que requiere interactuar poco con otros componentes en otras partes del programa.
En un módulo cohesivo, sus componentes están fuertemente relacionados entre sí y pertenencen al módulo por una razón lógica (no están ahí por casualidad), es decir, todos cooperan para alcanzar un objetivo común que es la función del módulo.
Un módulo cohesivo mantiene unidos (atrae) los componentes que están relacionados entre ellos y mantiene fuera (repele) al resto.
En pocas palabras, un módulo cohesivo debe tener un único objetivo, y todos los elementos que lo componen deben contribuir a alcanzar dicho objetivo.
Aunque siempre debe tratarse de lograr mucha cohesión (por ejemplo, una sola tarea), con frecuencia es necesario y aconsejable hacer que un módulo realice varias tareas, siempre que contribuyan a una misma finalidad lógica.
Sin embargo, para lograr un buen diseño hay que evitar módulos que llevan a cabo funciones no relacionadas.
La siguiente es una escala de grados de cohesión, ordenada de mayor a menor:
Cohesión funcional
Cohesión secuencial
Cohesión de comunicación
[Hasta aquí, los módulos se consideran cajas negras.]
Cohesión procedimental
Cohesión temporal
Cohesión lógica
Cohesión coincidental
No hace falta determinar con precisión qué cohesión tenemos. Lo importante es intentar conseguir una cohesión alta y reconocer cuándo hay poca cohesión para modificar el diseño y conseguir una mayor independencia funcional.
Cohesión funcional: se da cuando los componentes del módulo pertenecen al mismo porque todos contribuyen a una tarea única y bien definida del módulo.
Cohesión secuencial: se da cuando los componentes del módulo pertenecen al mismo porque la salida de uno es la entrada del otro, como en una cadena de montaje (por ejemplo, una función que lee datos de un archivo y los procesa).
Cohesión de comunicación: se da cuando los componentes del módulo pertenecen al mismo porque trabajan sobre los mismos datos (por ejemplo, un módulo que procesa números racionales).
Cohesión procedimental: se da cuando los componentes del módulo pertenecen al mismo porque siguen una cierta secuencia de ejecución (por ejemplo, una función que comprueba los permisos de un archivo y después lo abre).
Cohesión temporal: se da cuando los componentes del módulo pertenecen al mismo porque se ejecutan en el mismo momento (por ejemplo, una función que se dispara cuando se produce un error, abriría un archivo, crearía un registro de error y notificaría al usuario).
Cohesión lógica: se da cuando los componentes del módulo pertenecen al mismo porque pertenencen a la misma categoría lógica aunque son esencialmente distintos (por ejemplo, un módulo que agrupe las funciones de manejo del teclado o el ratón).
Cohesión coincidental: se da cuando los componentes del módulo pertenecen al mismo por casualidad o por razones arbitrarias, es decir, que la única razón por la que se encuentran en el mismo módulo es porque se han agrupado juntos (por ejemplo, un módulo de «utilidades»).
4.5.2 Acoplamiento
El acoplamiento es una medida del grado de interdependencia entre los módulos de un programa.
Dicho de otra forma, es la fuerza con la que se relacionan los módulos de un programa.
El acoplamiento depende de:
La complejidad de la interfaz entre los módulos.
El punto en el que se entra o se hace referencia a un módulo.
Los datos que se pasan a través de la interfaz.
Lo deseable es tener módulos con poco acoplamiento, es decir, módulos que dependan poco unos de otros.
De esta forma obtenemos programas más fáciles de entender y menos propensos al efecto ola, que ocurre cuando se dan errores en un sitio y se propagan por todo el programa.
Los programas con alto acoplamiento tienden a presentar los siguientes problemas:
Un cambio en un módulo normalmente obliga a cambiar otros módulos (consecuencia del efecto ola).
Requiere más esfuerzo integrar los módulos del programa ya que dependen mucho unos de otros.
Un módulo particular resulta más difícil de reutilizar o probar debido a que hay que incluir en el lote a los módulos de los que depende éste (no se puede reutilizar o probar por separado).
La siguiente es una escala de grados de acoplamiento, ordenada de mayor a menor:
Acoplamiento por contenido
Acoplamiento común
Acoplamiento externo
Acoplamiento de control
Acoplamiento por estampado
Acoplamiento de datos
Sin acoplamiento
No hace falta determinar con precisión qué acoplamiento tenemos. Lo importante es intentar conseguir un acoplamiento bajo y reconocer cuándo hay mucho acoplamiento para modificar el diseño y conseguir una mayor independencia funcional.
Acoplamiento por contenido: ocurre cuando un módulo modifica o se apoya en el funcionamiento interno de otro módulo (por ejemplo, accediendo a datos locales del otro módulo). Cambiar la forma en que el segundo módulo produce los datos obligará a cambiar el módulo dependiente.
Acoplamiento común: ocurre cuando dos módulos comparten los mismos datos globales. Cambiar el recurso compartido obligará a cambiar todos los módulos que lo usen.
Acoplamiento externo: ocurre cuando dos módulos comparten un formato de datos impuesto externamente, un protocolo de comunicación o una interfaz de dispositivo de entrada/salida.
Acoplamiento de control: ocurre cuando un módulo controla el flujo de ejecución del otro (por ejemplo, pasándole un conmutador booleano).
Acoplamiento por estampado: ocurre cuando los módulos comparten una estructura de datos compuesta y usan sólo una parte de ella, posiblemente una parte diferente. Esto podría llevar a cambiar la forma en la que un módulo lee un dato compuesto debido a que un elemento que el módulo no necesita ha sido modificado.
Acoplamiento de datos: ocurre cuando los módulos comparten datos entre ellos (por ejemplo, parámetros). Cada dato es una pieza elemental y dicho parámetro es la única información compartida (por ejemplo, pasando un entero a una función que calcula una raíz cuadrada).
Sin acoplamiento: ocurre cuando los módulos no se comunican para nada uno con otro.
4.6 Reusabilidad
La reusabilidad es un factor de calidad del software que se puede aplicar tambien a sus componentes o módulos.
Un módulo es reusable cuando puede aprovecharse para ser utilizado (tal cual o con muy poca modificación) en varios programas.
A la hora de diseñar módulos (o de descomponer un programa en módulos) nos interesa que los módulos resultantes sean cuanto más reusables mejor.
Para ello, el módulo en cuestión debe ser lo suficientemente general y resolver un problema patrón que sea suficientemente común y se pueda encontrar en varios contextos y programas diferentes.
Además, para aumentar la reusabilidad, es conveniente que el módulo tenga un bajo acoplamiento y que, por tanto, no dependa de otros módulos del programa.
Esos módulos incluso podrían luego formar parte de una biblioteca o repositorio de módulos y ponerlos a disposición de los programadores para que puedan usarlos en sus programas.
A día de hoy, el desarrollo de programas se basa en gran medida en seleccionar y utilizar módulos reusables (que en este contexto también se denominan bibliotecas, librerías o paquetes) desarrollados por terceros o reutilizados de otros programas elaborados por nosotros mismos anteriormente.
Es decir: la programación se ha convertido en una actividad que consiste principalmente en ir combinando módulos intercambiables.
Eso nos permite acortar el tiempo de desarrollo porque podemos construir un programa a base de ir ensamblando módulos reusables como si fueran las piezas del engranaje de una máquina.